今週:先週話していたテキストファイルに関しては分ける方向で進める。少し不便だが、見辛いよりマシかと。また音とシーン分類の精度向上させる為に色々考えてはいるが、まだこれといったものが思い浮かんではいない。1案として、librosa を導入して、inaspeechsegmenterと一緒に、時間と波形を見て分類の補助っぽい役割にしようかなと考えている。精度など数値で出せるかは不明
来週:2dcnnのみでシーン分類を行い、その精度を確認する実験と、上記の内容を考えながら進めていく。
発表資料の作成

今週:先週話していたテキストファイルに関しては分ける方向で進める。少し不便だが、見辛いよりマシかと。また音とシーン分類の精度向上させる為に色々考えてはいるが、まだこれといったものが思い浮かんではいない。1案として、librosa を導入して、inaspeechsegmenterと一緒に、時間と波形を見て分類の補助っぽい役割にしようかなと考えている。精度など数値で出せるかは不明
来週:2dcnnのみでシーン分類を行い、その精度を確認する実験と、上記の内容を考えながら進めていく。
発表資料の作成
今週:卒論α版の作成、メインプログラムに音声区間認識のプログラムの挿入。
結果の印字は一つのテキストファイルに出るようにした。既存の結果印字が少しわかりにくくなったので、別のファイルに印字することも視野に入れている。
ただし付け加えたという形なのでこれを精度向上という風にどう工夫するか来週までに考えて実装したい。現状考えているのは、
来週は上記の内容をやる。
今週やった事
複数のライブラリの追加
inaSpeechSegmenter : 入力した音声ファイルを無音、会話、bgmなどに区分してテキストで出力してくれる。
ffmpeg-python : 映像を音声ファイルに変換する。今回は.mp4を.wavへ変換
VOSK : 音声ファイルを自動で文字で書き上げてくれる。
githubからコードを持ってくる予定だったが、こちらを使う予定は今のところなし
来週までにやる事
変換作業は終わったので、mainプログラムと組み合わせる。
3dcnnの実装について、学習データの量や時間の足りなさ、また3dcnnの使用部分がプレイ詳細にしか使用しないことなどを踏まえ、シーン遷移に使用するためには使用しないので、今回省く事に決定。
来週までに使用するライブラリに使用できる拡張子を調べそれに変換する。
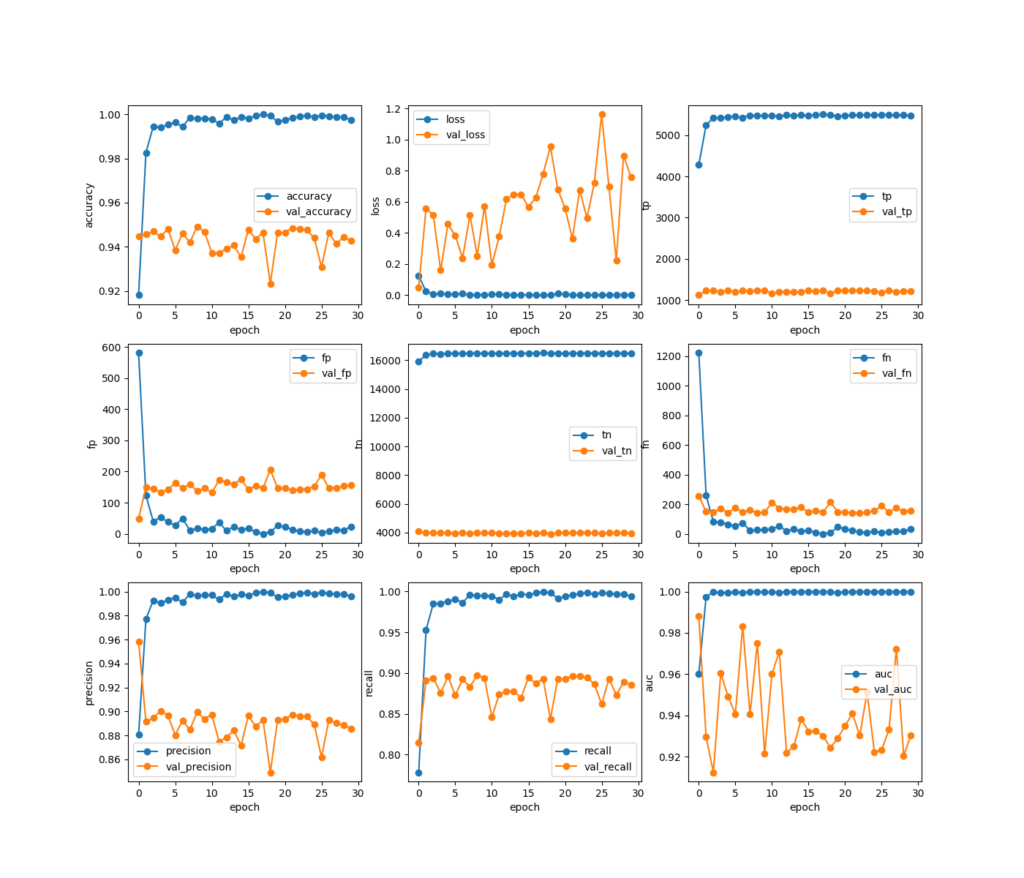
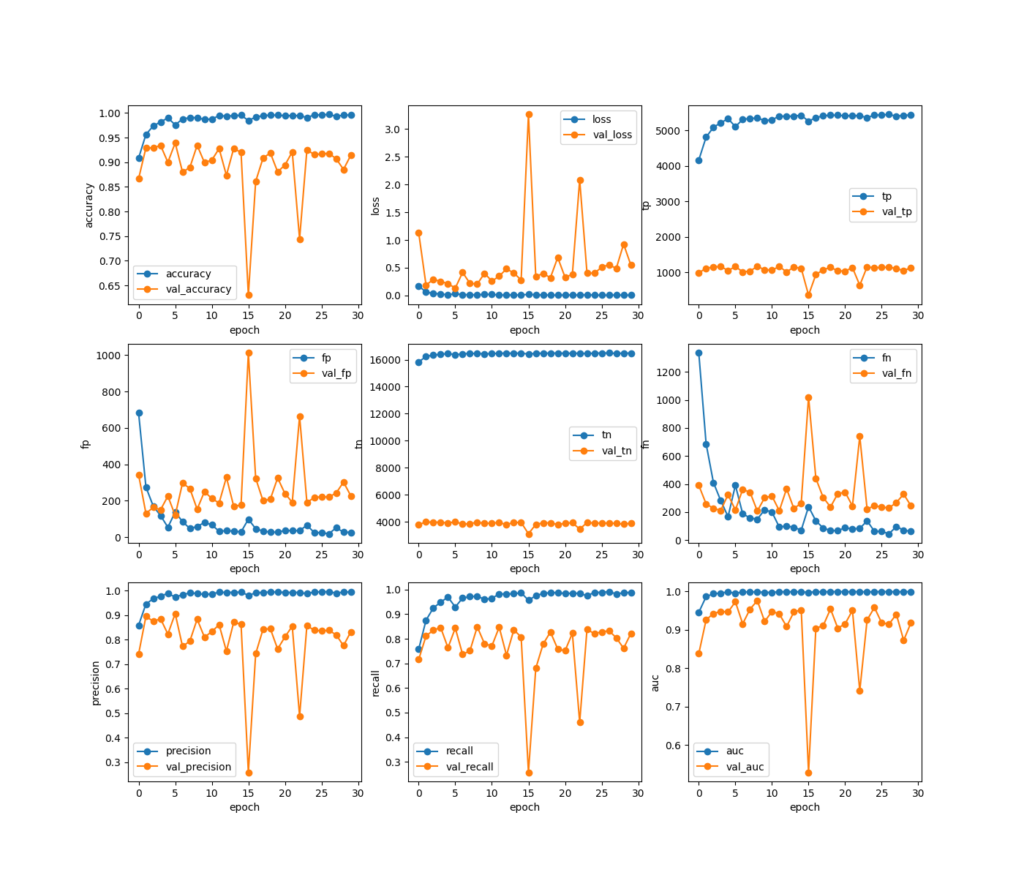
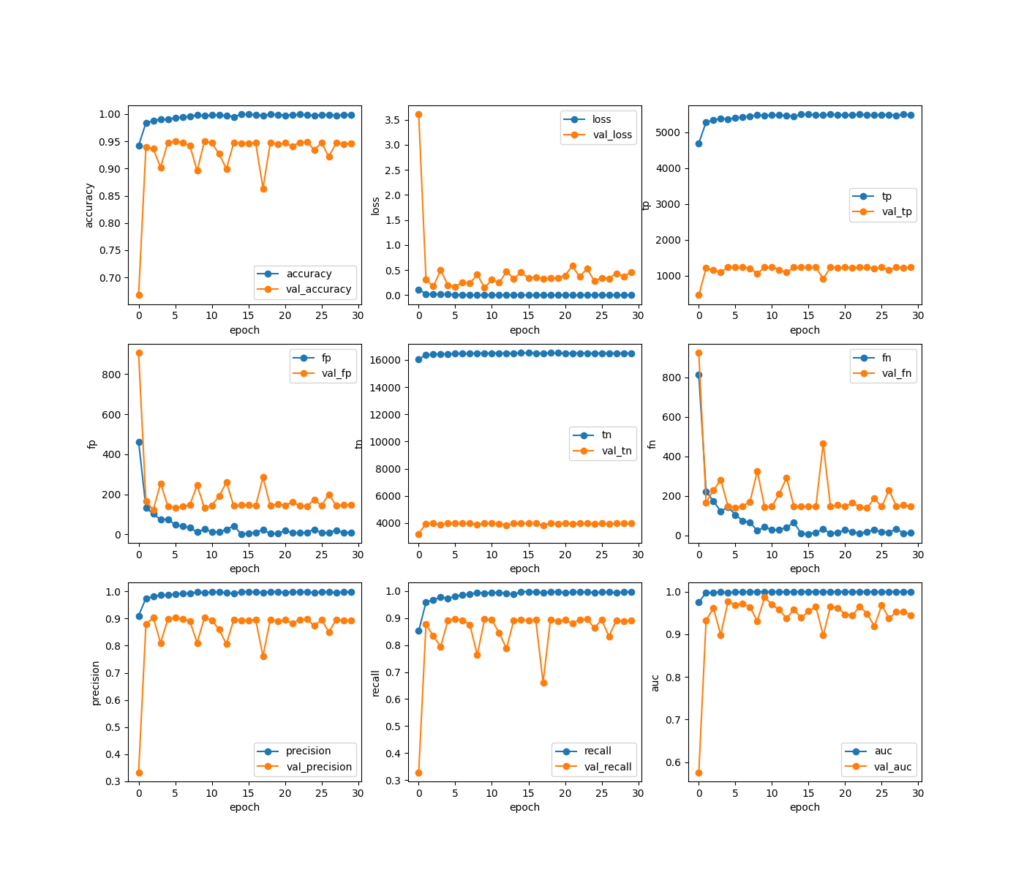
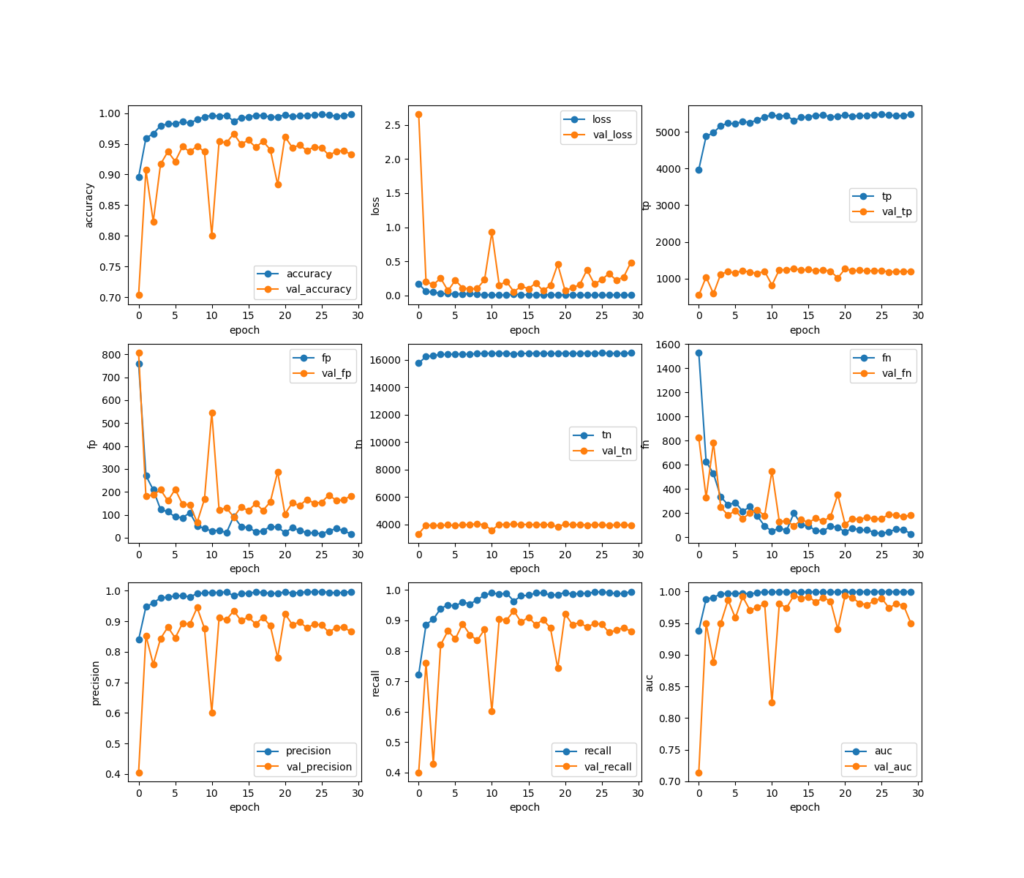
2dcnnによるモデルの完成。
来週までにやること
3dcnnのモデルを完成させ、音声を省いたメインプログラムを実行した結果を共有できるまで。その後課題である音声のプログラム製作などに取り掛かりたいと思っている。
今週は先週と引き続き、dateset_dirにデータに格納しない問題の解決に取り組んでいました。
先生に相談して、引き続き解決に取り組みます。
来週は報告会に向けて資料の製作及び上記の問題の解決に向けて進みます。
今週行ったこと。
データセットに必要な動画を画像に変換したりなど
2dcnnのプログラム内容の確認と、変更。ファイルの場所など
データの内容を読み取ってもらえない状態。CUDAなどは機能してるみたいです。
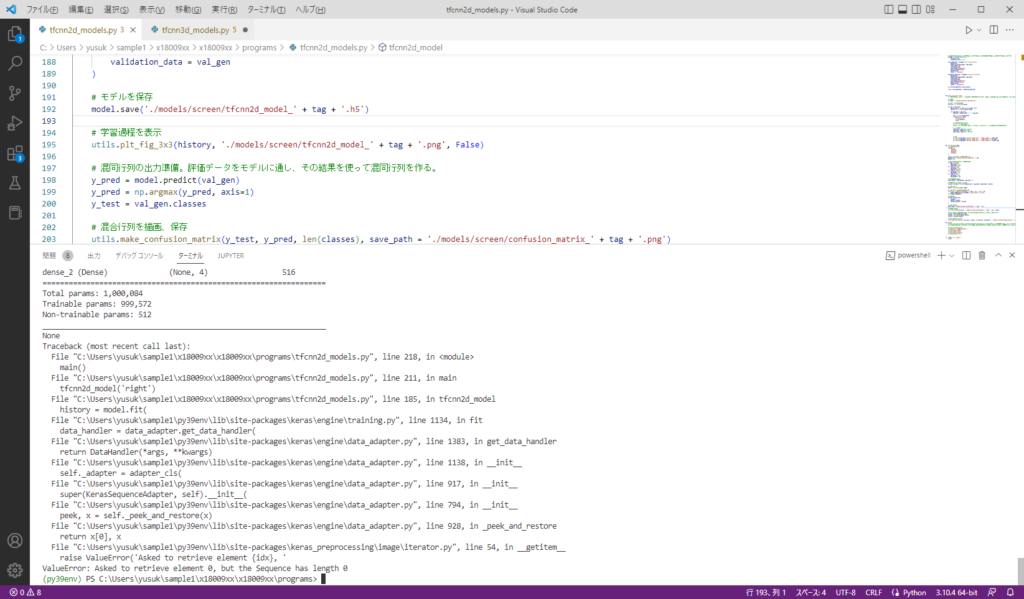
来週までにやること。
データセットを読み取ってくれない問題を解決。
引き続きデータを増やす。
1.環境の変更
バージョンの互換性の問題で、python3.10からpython 3.9に、CUDA11.8から11.2に変更など
2.学習用データの構築
現在、とりあえず音を無視した状態で勉強させている。それを作り終わってから後について着手する。
3.今後
データセットを最優先、その後音についてどう学習させるかなど
CUDA を使うための環境構築を行っていました。
今週は体調が悪くあまり進んでいません。
来週:CUDAの環境構築を終わらせる。
今週:OpenCV, Keras, Seaborn, CUDA (NVIDIA), Matplotlibのインストール。
main.pyを動かすためのライブラリ等のインストールを終えました。
しかし、main.pyを動かそうとするとエラーを吐く。
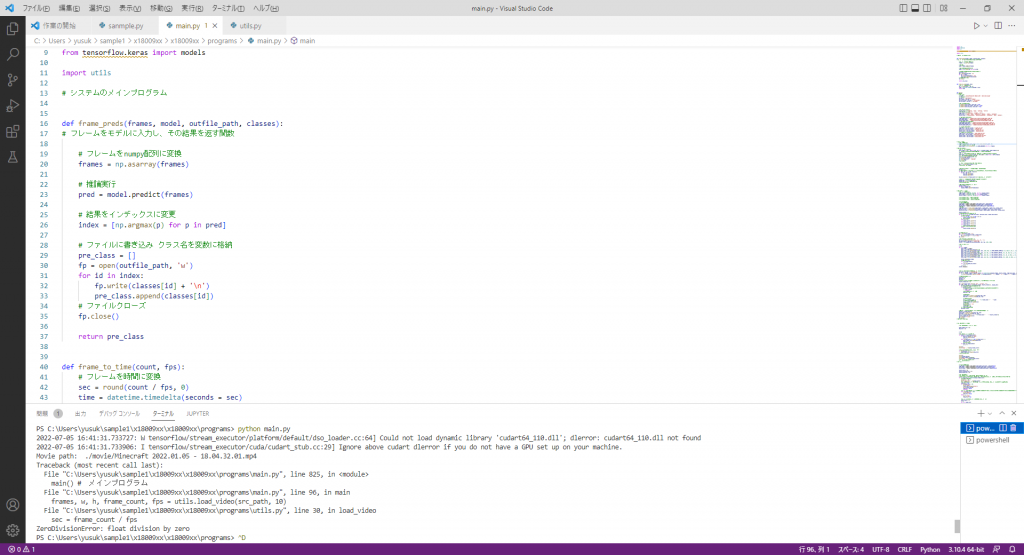
来週:先輩に相談した結果、tensorflowでGPUを使用する設定ができていない可能性を提示されたので、それを試してみる。
長期的:学習用モデルの撮影を行います。