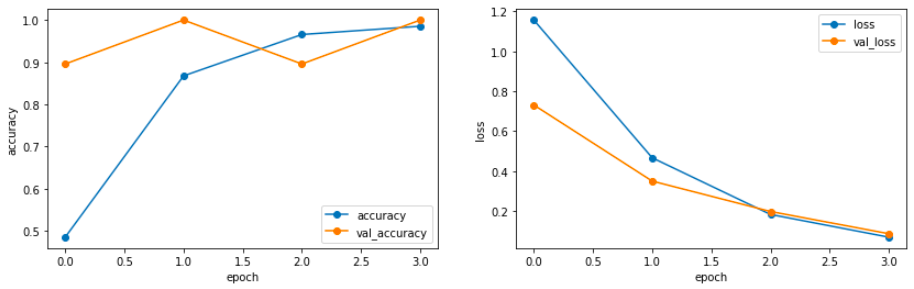
前回水増しした画像を学習用データとして、VGG16というモデルを使用し,ファインチューニングを行いました。
下のグラフは学習結果を可視化したもので、左のグラフは1.0に近ければ近いほど良く、右のグラフは小さければ小さいほど良いので、学習が上手くいっていることがわかりました。
学習結果の描写画像が判別されるかどうかを一種類ずつ、学習用の画像とは違う画像で確認したところ、3種類全ての画像を正しく判別できました。
学習用データの元の画像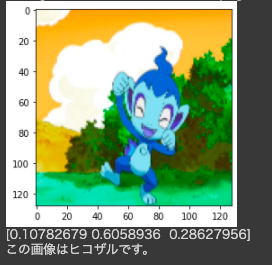
判別結果前回水増しした画像を学習用データとして、VGG16というモデルを使用し,ファインチューニングを行いました。
下のグラフは学習結果を可視化したもので、左のグラフは1.0に近ければ近いほど良く、右のグラフは小さければ小さいほど良いので、学習が上手くいっていることがわかりました。
学習結果の描写画像が判別されるかどうかを一種類ずつ、学習用の画像とは違う画像で確認したところ、3種類全ての画像を正しく判別できました。
学習用データの元の画像判別結果