
研究の概要

画像・映像・3D・動き情報などのデータを用い,文字入力しなくても身の回りの情報を適切に入手できるような認識・検索・機械学習技術に関する研究に取り組んでいます.
楽しさや便利さを追求しつつ,人の役に立ち生活の質(QoL: Quality of Life)を高めるアプリ・サービスの実現を目指します.
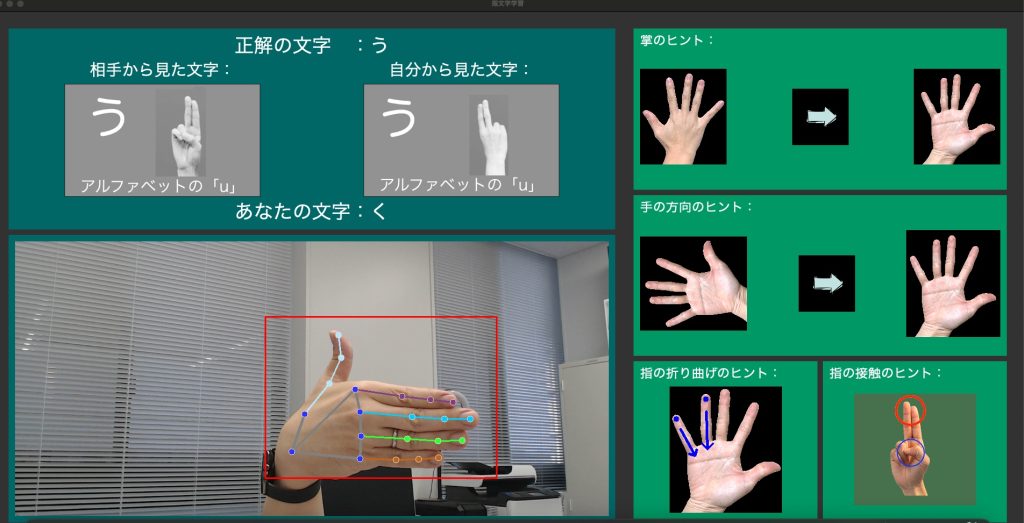
研究例:手話学習支援
技術ポイント:動作認識,ゲーミフィケーション

手話の一つである指文字を自主学習するアプリケーションの開発を進めています.2020年度までは,Leap Motion Controllerと呼ばれるモーションセンサを用いて動作認識を行いました.学習モードでは画面左側に表示される五十音とその指文字の3D CGを見て,その模倣を行います. 画面上部のモーションセンサで手指の形状や動作を取得し,画面右側にリアルタイムで表示を行うと同時に,模倣できているかどうか認識を行います. 正しく模倣できている場合には、花丸が表示されます.テストモードやゲームモードでスコアを競うことで,繰り返し学習への動機づけを行います.
動作を計測するモーションセンサは,その一方でアプリケーション導入の障壁になります.そこで2021年度からは,RGBカメラだけを用いた指文字認識手法の研究を進めています.Googleが開発した深層学習ライブラリMediaPipeを用い,学習者が間違えた模倣箇所をリアルタイムで指摘可能な自主学習支援アプリケーションを開発しています.
研究例:農作物画像からの属性推定
技術ポイント:画像認識、深層学習

農作物の品質や美味しさを消費者が容易に知るため,また生産者が生育状況や採取時期を判断する情報提供のため,農作物の外観画像からその糖度や腐敗度合いなどの属性情報を推定する研究に取り組んでいます.具体的には,手に触れて確認することが難しい桃を対象にして,その美味しさの基準である糖度(甘さ)を画像から推定する手法を,ディープラーニング(深層学習)モデルをハイブリッドに用いることで実現しています.
桃画像の糖度推定アプリケーションでは,スマートフォンを用いて桃の画像を撮影し糖度推定サーバに送信します.サーバはその画像を用いてハイブリッドディープラーニング手法により糖度の推定を行います. その結果を画面に表示し,その状態を確認することができます.
主な研究内容
上記のようなサービス・アプリケーション実現のためには
- さまざまなデバイスでメディア情報を取得する技術
- 取得されたメディア情報を用いて正しく認識・検索を行う技術
- サービスとしての魅せ方や利用者への適切な提示を行う技術
- 上記技術に基づく機能実現のためのプラットフォーム技術
などが必要となります.当研究室ではこれらの技術開発を目指し,
- 画像・映像・3次元・動作などのメディア情報を用いた認識・検索・機械学習(認識系AI)に関する研究
- 利用者への適切な認識・検索情報提示手法に関する研究
- QoL向上に向けたサービス・アプリケーションとしての実現手法に関する研究
などの課題を設定して,これらの研究を進めます.