今週やったこと
YOLOの精度向上について調べていて出てきた、以下の記事を読んでいました。
【albumentations】データ拡張による精度向上を検証する – Qiita
記事内では、すでに用意されているデータセットの画像に
・左右反転
・回転
・切り抜き
・モザイク
の処理を施した画像を追加し、そのデータセットを学習させて精度がどのように変化するかという検証を行なっていました。
結果から言えば、反転・回転を施した画像のみを追加したデータセットが一番精度が高かったようです。
この記事では単体クラス(小麦のデータセット)に対してデータ拡張を行なっているため、多クラスの場合どうなるかは不明です。
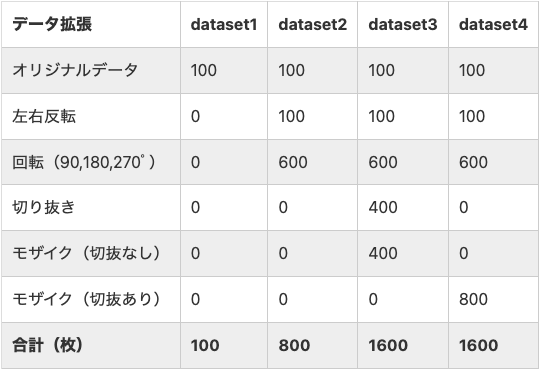
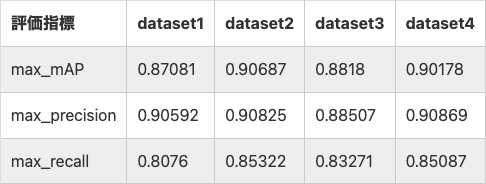
自分の研究ではなるべく多くの画像を用意するようにはしていますが、画像数が足りない場合は、こういったデータの増やし方も検討しようと考えています。
来週やること
- 学習画像の撮影
- アノテーションデータの作成