今週やったこと
今週は評価実験用に、硬貨の画像の撮影を行い、総数200枚→400枚になりました。
他は、α版の作成に時間を取られていたので、大きな進捗はありません。
来週やること
- α版の修正
- 評価実験用の画像撮影
- 進捗発表の資料作成
今週やったこと
今週は評価実験用に、硬貨の画像の撮影を行い、総数200枚→400枚になりました。
他は、α版の作成に時間を取られていたので、大きな進捗はありません。
来週やること
今週やったこと
先週の結果から、硬貨のデータセットで一部アノテーションの座標が本来の場合とズレている画像や、領域が正しく囲えていない画像があったため、これらを修正しました。
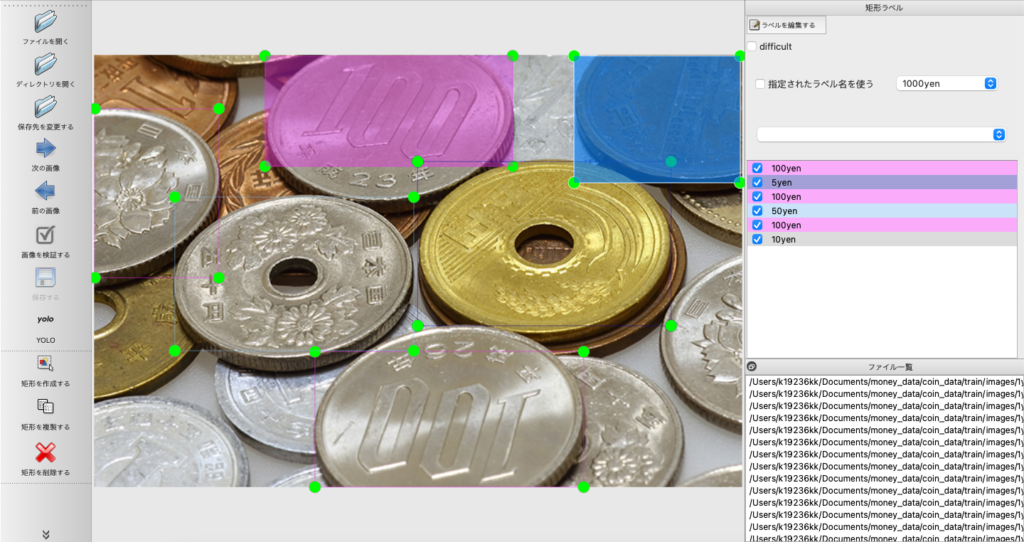
先週の進捗にあった丸い模様の誤検出への対策は、丸い模様を背景にした画像をデータセットに入れて再学習を行なってみようと考えています。
来週やること
今週やったこと


紙幣と似ている色の文字入りの紙袋を背景とし、平面や折った状態で撮影を行い、各画像に寒色・暖色のフィルタをかけて画像数を3倍にしました。(合計700枚程度)
YOLOv7で硬貨と紙幣の各モデルをGoogle Colab ProのGPU環境で学習しました。
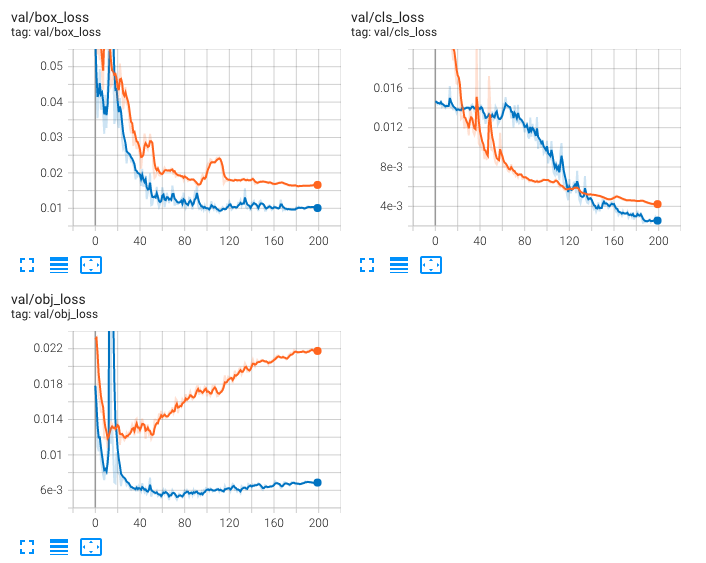
硬貨のobj_lossが途中から大きくなっているので、過学習の可能性があり、再度条件を変更しつつ撮影を行う必要がありそうです。
紙幣はいい感じに収束していると思われます。
まず紙幣のモデルで物体検出を行った後、硬貨のモデルで検出を行ないました。


中間発表の課題であった、縦・斜めの紙幣の検出ができるようになりました。背景や折りに関係なく正解率もかなり高いので、精度は充分だと思います。


現在までの課題であった、紙幣と硬貨の同時検出ができました。


問題点として、紙幣などの円の形を硬貨として検出をしてしまう場合があり、これの対策として、学習データに紙幣を背景とした画像を用いることが有効だと考えました。
Google Colab Proにアップグレードしたので、学習時間が30時間から7時間に短縮された。また、Drive内から実行すると一回の学習で10GBほど持っていかれる。
物体検出にかかる時間は平均25ms。
来週やること
今週やったこと
照明条件を変更して硬貨の撮影を行いました。
また、これまでに使用していた(上で撮影した画像は含まない)データセットでYOLOv7の再学習を行いました。



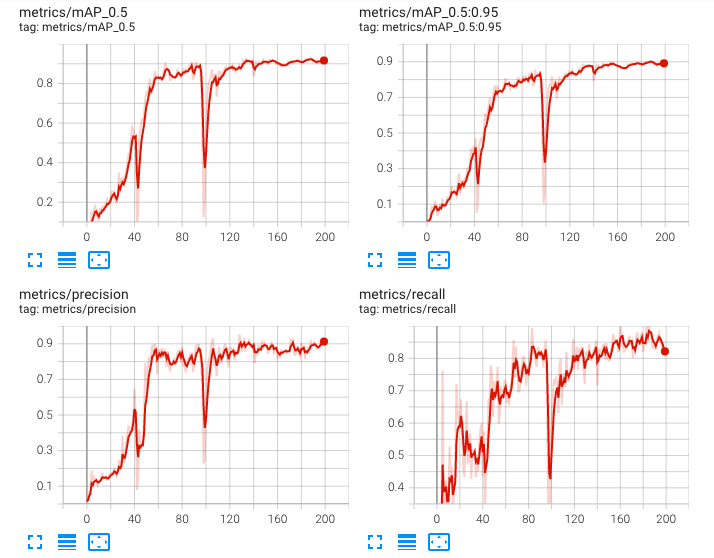
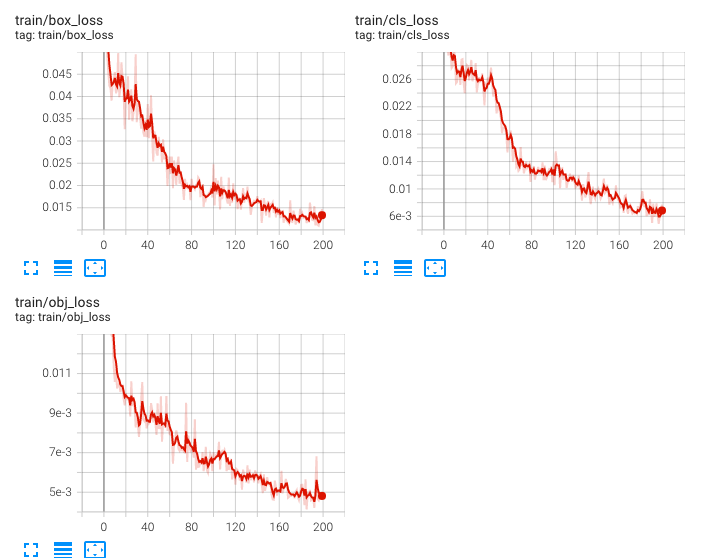
5円玉と10円玉以外の正解率がかなり高いので、今後はYOLOv7を採用しようと考えています。
今後はAlbumentationなどでのデータ拡張も考えていますが、YOLOv7で実装できない場合は、引き続きYOLOv5を使用します。
来週やること
今週やったこと
https://kikaben.com/object-detection-non-maximum-suppression/
上記サイトを参考にNMSのを確認していました。

IoUについては理解できましたが、「multi_label」という変数についてはYOLOv5でのオリジナルの仕様っぽく、まだイマイチ理解できていないので、もう少し調べる必要がありそうです。
また、IoUの閾値や「multi-label」をTrueにしての学習に関しては、既存研究の資料作成で時間をかけてしまったため、まだできていません。
来週までにやること
やったこと
中間発表での課題となっていた、大きい物体に小さい物体が完全に重なっている場合のYOLOv5の調査をしていました。
今回の研究では下の画像のように紙幣の上に硬貨が重なる状況が課題になると考えられています。

「ディープラーニングによる物体検知技術 YOLOv5を用いた図面要素抽出の研究」(2022.3, 神戸大学都市安全研究センター)
http://www.rcuss.kobe-u.ac.jp/publication/Year2022/pdfEach26/26_03.pdf
https://blog.negativemind.com/2019/02/21/general-object-recognition-yolo/
YOLOの構造や他の物体検出の構造を調査した結果、Bounding Box(矩形領域)の推定の際に、Non-Maximum Suppression(NMS)というアルゴリズムを適用しているため、重なっている硬貨が検出されないのではないかと推測しました。
物体検出モデルはたくさんの重なりあったBounding Boxを予測するが、これにNMSと呼ばれる後処理を加えることで確実性の高いBounding Boxのみを残すことができる。
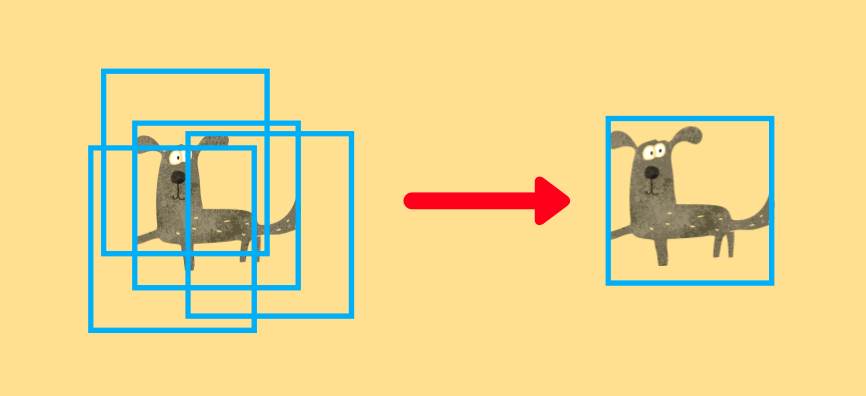
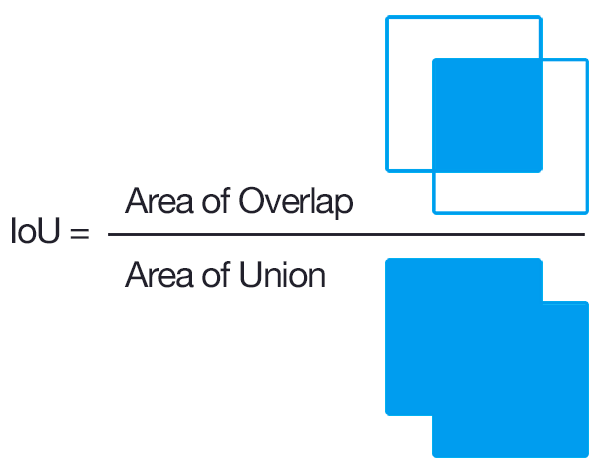
IoUとは、画像の重なりの割合を表す値である。
IoU値が大きいほど、画像が重なっており、IoU値が小さいほど、画像が重なっていない状態となる。
実際にNMSの閾値を調整すれば、完全な重なりも検出できるようになるかもしれないと考え、今回はNMS関数内の閾値を0.25から0.50に変更してもう一度硬貨のみを再学習させてみました。
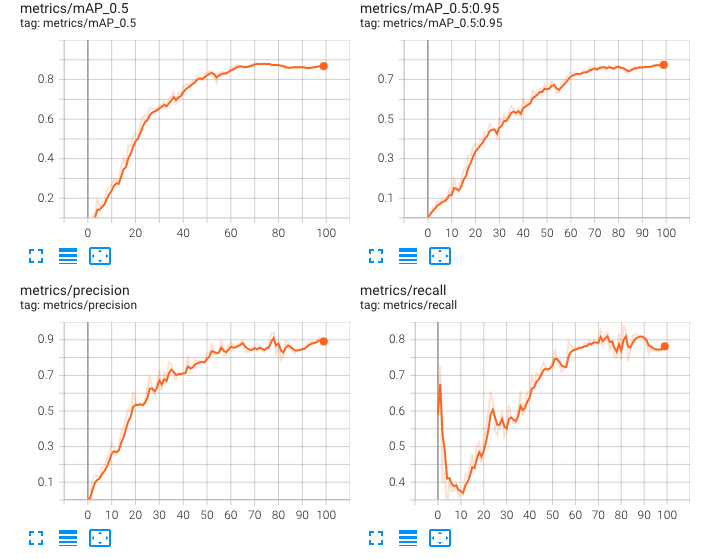




結果として調整前と調整後では、想定とは逆に、完全な重なりだけでなく一部の重なりに対しても弱くなってしまいました。
後でコードを見返した結果、どうやら調整したのはスコアの閾値だったようで、そのため、逆に精度が悪くなってしまったと考えられます。

次回までに上記のNMS関数の仕様を理解して、IoUを変更した場合に結果がどう変わるのかを検証します。
次回までにやること
今週やったこと
YOLOの精度向上について調べていて出てきた、以下の記事を読んでいました。
【albumentations】データ拡張による精度向上を検証する – Qiita
記事内では、すでに用意されているデータセットの画像に
・左右反転
・回転
・切り抜き
・モザイク
の処理を施した画像を追加し、そのデータセットを学習させて精度がどのように変化するかという検証を行なっていました。
結果から言えば、反転・回転を施した画像のみを追加したデータセットが一番精度が高かったようです。
この記事では単体クラス(小麦のデータセット)に対してデータ拡張を行なっているため、多クラスの場合どうなるかは不明です。
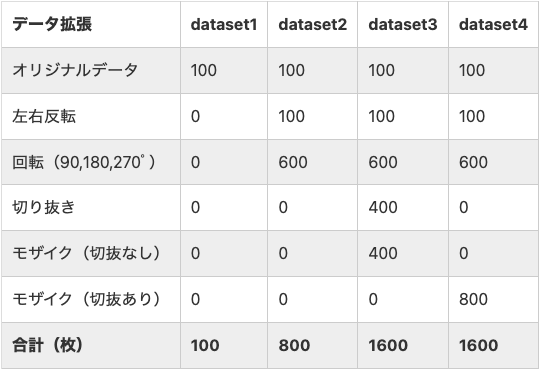
自分の研究ではなるべく多くの画像を用意するようにはしていますが、画像数が足りない場合は、こういったデータの増やし方も検討しようと考えています。
来週やること
今週やったこと
YOLOv5を使用している研究として、以下の論文を読んでどのような研究がされているのかを確認していました。
・YOLO5Face: Why Reinventing a Face Detector(2022.1.27)
・Evaluation of YOLO Models with Sliced Inference for Small Object Detection(2022.3.9)
後者の研究では、YOLOv5とSlicing Aided Hyper Inference (SAHI)を組み合わせて推論を行なっていました。(SAHIは小さい物体を検出するのに強いらしい)
学習時には元の画像を分割し、分割した画像をそれぞれ学習させる手法を取っていました。

やはり精度を高めるために複数の物体検出手法を組み合わせている研究が多いようなので、自分の研究でも精度を確認しつつ、場合によっては検討すべきと考えています。
来週やること
今週やったこと
前回のエラーがどうしても直らず、アノテーションデータを再作成しても画像を変えても解決できなかったので、YOLOv5側でdogの画像を学習させて、とりあえず精度と速度を比較することにしました。
<YOLOv5>
<SSD>

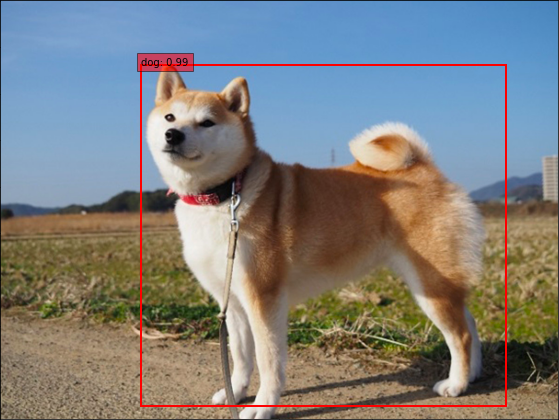






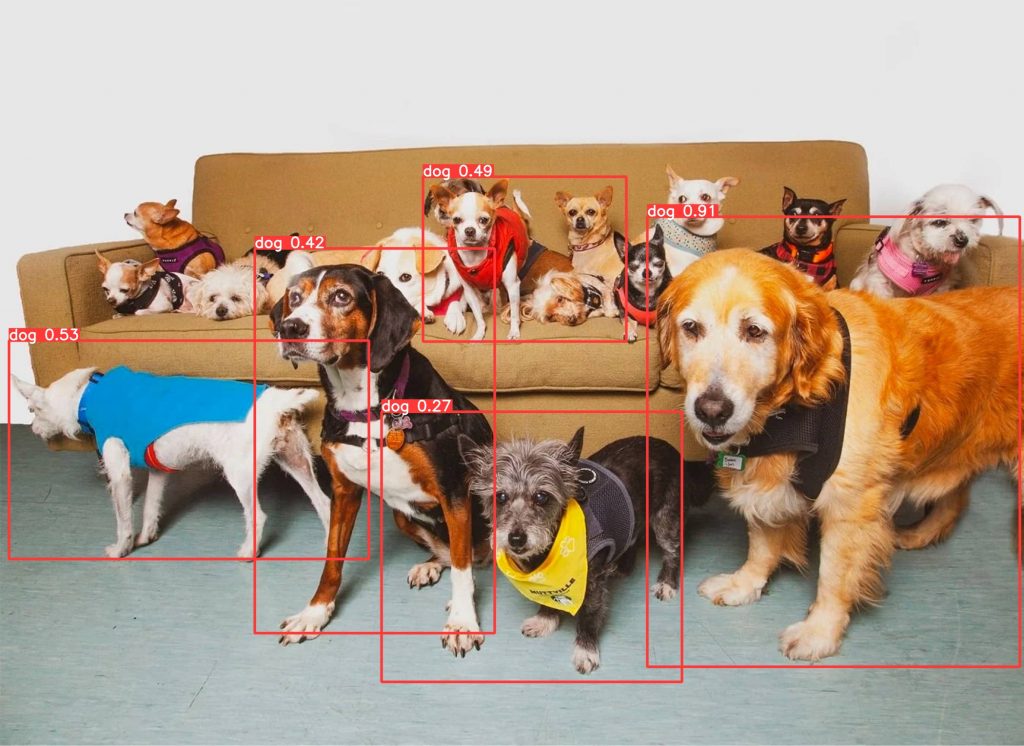

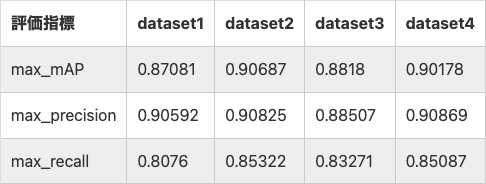
精度自体はSSDの方が良い数値を出しており、単体の検出精度は良いですが、複数検出はできていませんでした。
YOLOv5(yolov5s)はあまり良い数値は出ていませんが、複数検出がしっかりできていて、推論速度もSSDより高速でした。
また、YOLOv5の精度に関して、学習過程をグラフで確認すると60回前後で収束していると思われるので、過学習により精度が悪くなっているのではないかと考えています。
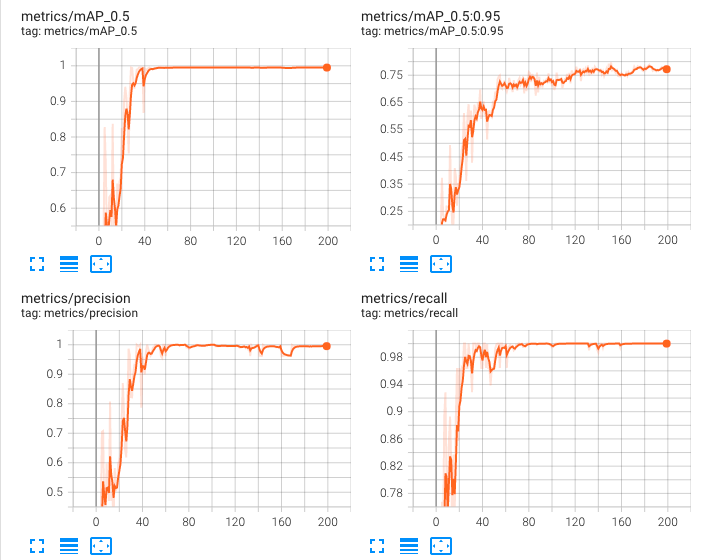
今回の結果から、これからYOLOv5(最軽量のyolov5sモデル)を使って物体検出をやっていくことに決定しました。
来週やること
今週やったこと
下記サイトを参考にPytorchでSSDの転移学習を試みていましたが、途中でエラーが出てうまく学習まで出来ませんでした。

エラーの原因はimgにうまく画像を取得できていないことだと思われるのですが、早急にエラーを解決してYOLOv5と精度や速度の比較し、来週までにどちらの物体検出技術を使うのかを決定したいです。
来週までにやること