今週は数種類のパターンで学習を行っていました。
(batch_size : 16, train : 7660枚, test : 3284枚)
- EfficientNet B2
- Xception (FineTuning, float)
- Xception (FineTuning, uint)
- Vgg16 (FineTuning)
以上の4パターンで学習を行いました。
以下が学習結果です。
- EfficientNet B2
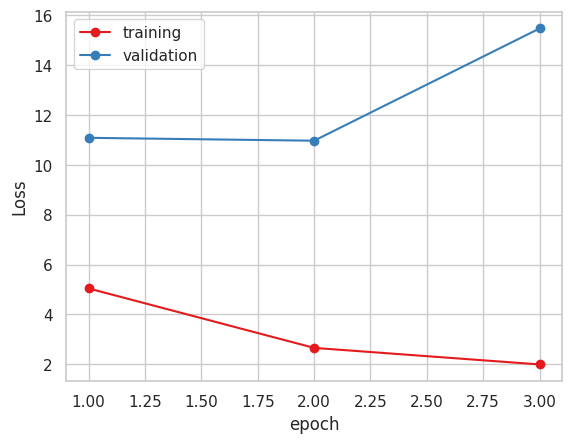
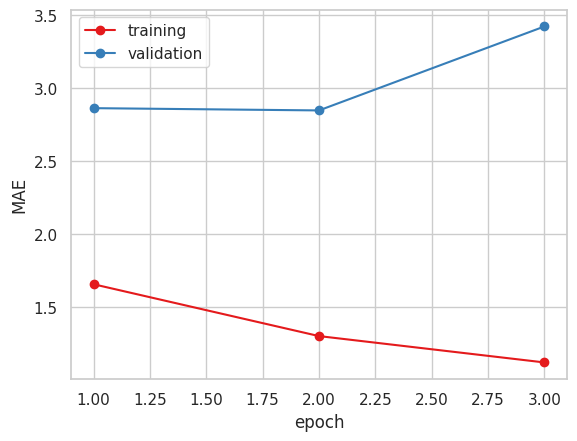
2. Xception ( 糖度データ 小数値 )
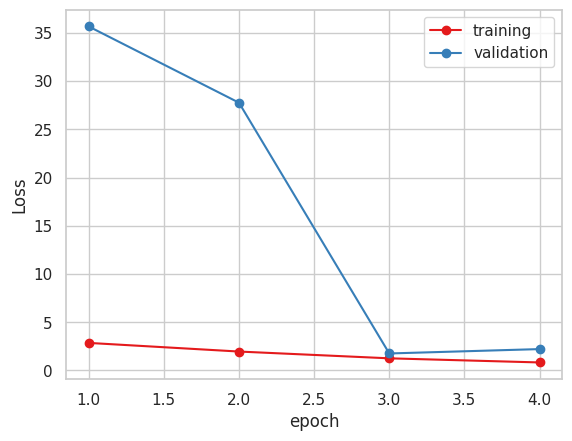
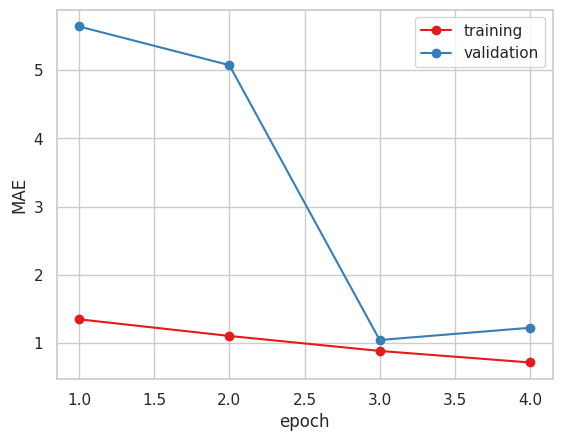
4. Vgg16
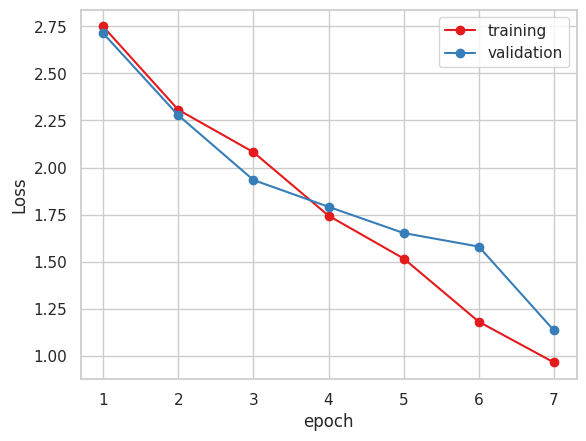
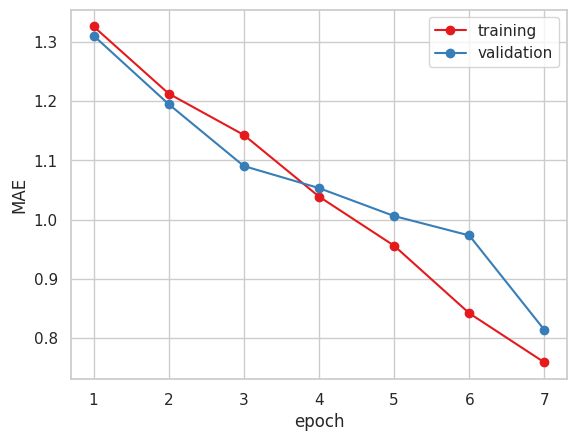
今まで指標にしていたMAEだけで見るとVGG16かXceptionが良いと思われます。
一部残していたデータを用いて精度検証を行いました。
MSEとMAE、決定係数 R2 を算出しました。
| No. | Name | MAE | MSE | R2 |
| 1 | EfficientNet B2 | 3.049 | 12.171 | -3.316191625399121 |
| 2 | Xception (float32) | 2.092 | 5.918 | -1.0984957912248525 |
| 3 | Xceptiom (uint8) | 1.5 | 3.661 | -0.24255871847602561 |
| 4 | Vgg16 | 1.637 | 4.470 | -0.585332572479959 |
R2を算出したところ、マイナス値になってしまっており、結構悪いと思われます。
糖度データを四捨五入して学習した時の方が精度が良いため、他のモデルでも試してみたいと思います。
次の予定としては、学習回数がまだまだ少ないため、VGG16モデルでの学習を続けるとともに、新たに桃部分のヒストグラムを入力値としたモデルを作成し、マルチモーダル、アンサンブルを行ってみようかなと思っています。
また、損失関数を自作(RMSE)に変えたところ、学習時間が同一モデルで1epochあたり2時間から1時間半に減りました。
GoogleColabの同時実行可能なノートブックが最高2つ(GPU, TPU ひとつずつ)だったため、複数モデルの学習が同時並行できそうです。