様々な学習を行っていました。
以前言っていたTPU学習をPytorchで実装しました。
TPUメモリが1コア8GBで8コアあるっぽいのですが、並列処理を行おうとしました。
画像とラベルデータをTPUメモリに載せようとしましたが、単なるメモリにしか乗らず、クラッシュしたため断念しました。
結局TensorFlowを用いてGPUでの学習を行っています。
EfficientNetB3をFinetuningしていますが、精度が一定の値から下がらず困っています。
様々な学習を行っていました。
以前言っていたTPU学習をPytorchで実装しました。
TPUメモリが1コア8GBで8コアあるっぽいのですが、並列処理を行おうとしました。
画像とラベルデータをTPUメモリに載せようとしましたが、単なるメモリにしか乗らず、クラッシュしたため断念しました。
結局TensorFlowを用いてGPUでの学習を行っています。
EfficientNetB3をFinetuningしていますが、精度が一定の値から下がらず困っています。
今週は別のモデルで学習を試していました。
EfficientNetB3がパラメータ数が少ない割にimagenet等での精度が良いため、転移学習を行なってみました。
結果は学習が全然進まなかったです。
GPUで行ったところ、学習が早く、今までTPUが使えてなかった疑惑が浮上しました。
今までは全画像を読み込まず、バッチサイズ分だけ画像読み込みして、学習を行う(fit_generator)ことで、メモリの使用を抑えていましたが、TPUを使用するとなるとtensorflowではできないかもしれないので、Pytorchも検討しています。
また、自作モデルで学習してみたところ、既存モデルを使用したFinetunigや転移学習と大した差は出なかったです。
まだ複数入力のモデルができていないため作成を行い、TPUを使用できているかを早めに確認したいと思います。
VGG16のFineTuningを引き続き行っていました。
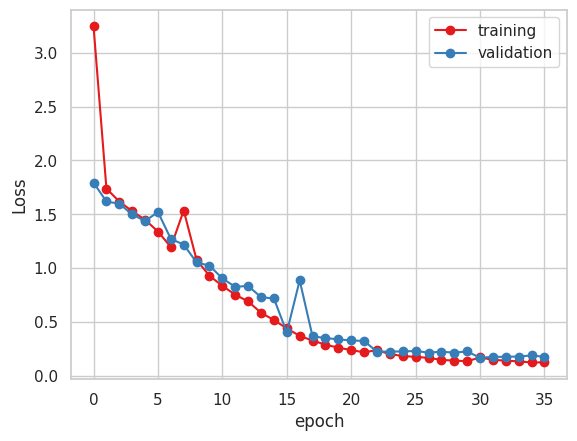
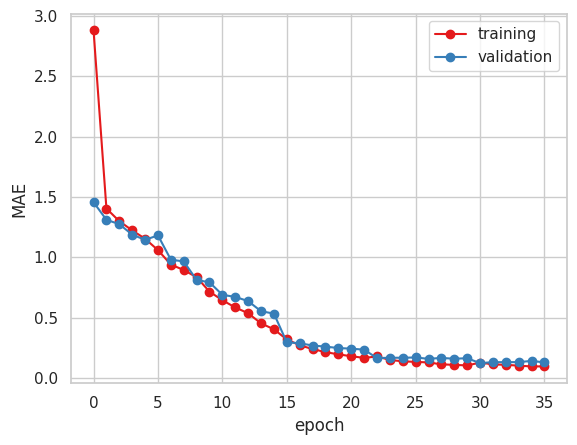
収束はしていそうですが、学習後に検証を行ったところ、決定係数R2は前回からあまり改善できていない状況です。
現在は、VGG16を3つ使用したアンサンブル学習を行っています。
GoogleColab上に画像データのフォルダを解凍するようにしたところ、batch_sizeが64で学習できたため、アンサンブル学習も問題なくできそうです。
どういったデータを入力値として増やすのに適切か考え、今週にも新しく学習に取りかかりたいです。
今週は数種類のパターンで学習を行っていました。
(batch_size : 16, train : 7660枚, test : 3284枚)
以上の4パターンで学習を行いました。
以下が学習結果です。
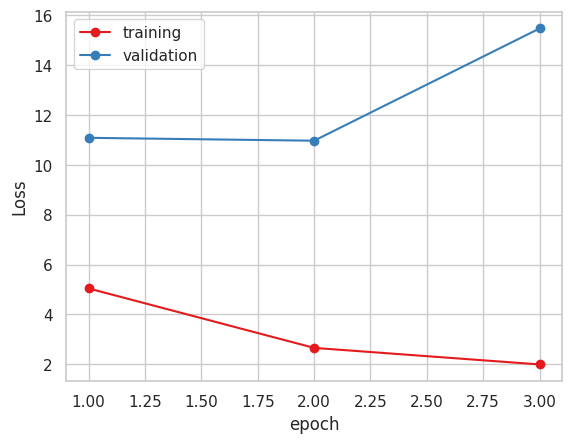
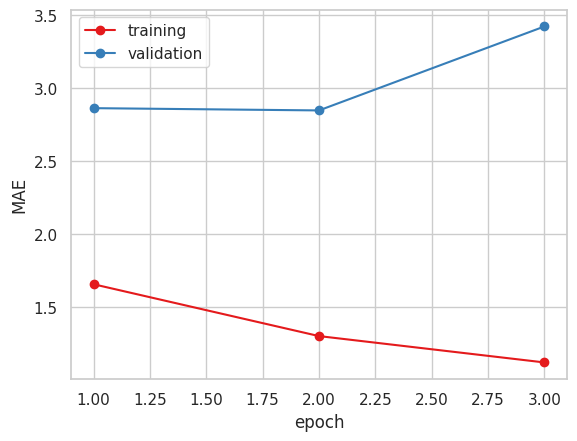
2. Xception ( 糖度データ 小数値 )
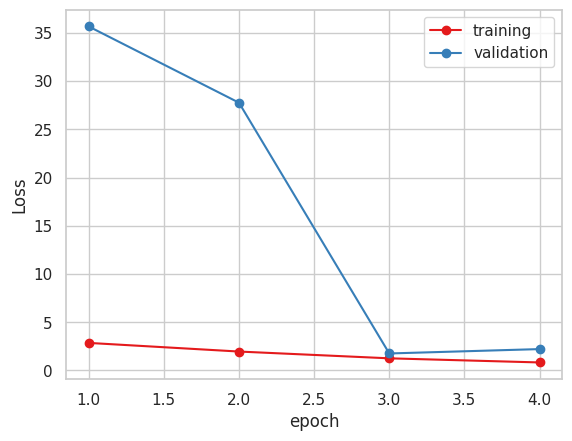
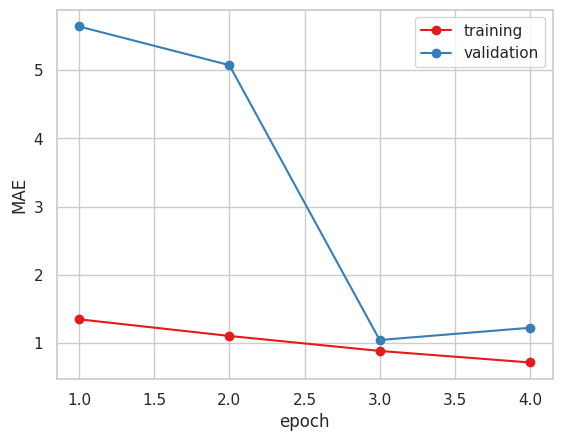
4. Vgg16
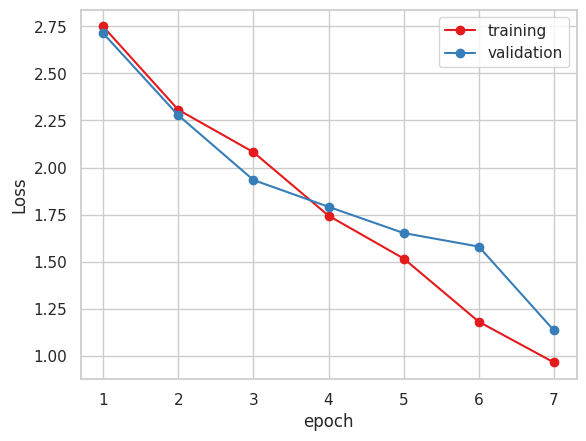
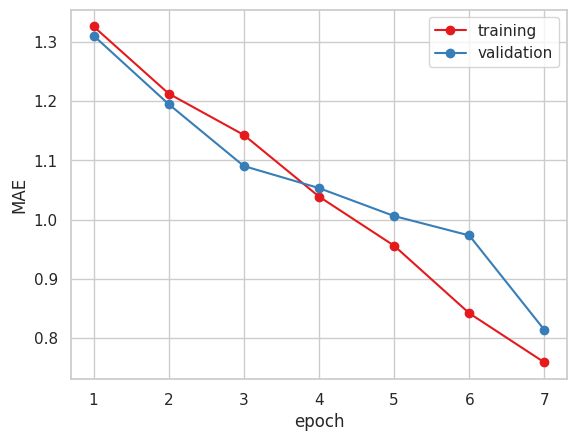
今まで指標にしていたMAEだけで見るとVGG16かXceptionが良いと思われます。
一部残していたデータを用いて精度検証を行いました。
MSEとMAE、決定係数 R2 を算出しました。
| No. | Name | MAE | MSE | R2 |
| 1 | EfficientNet B2 | 3.049 | 12.171 | -3.316191625399121 |
| 2 | Xception (float32) | 2.092 | 5.918 | -1.0984957912248525 |
| 3 | Xceptiom (uint8) | 1.5 | 3.661 | -0.24255871847602561 |
| 4 | Vgg16 | 1.637 | 4.470 | -0.585332572479959 |
R2を算出したところ、マイナス値になってしまっており、結構悪いと思われます。
糖度データを四捨五入して学習した時の方が精度が良いため、他のモデルでも試してみたいと思います。
次の予定としては、学習回数がまだまだ少ないため、VGG16モデルでの学習を続けるとともに、新たに桃部分のヒストグラムを入力値としたモデルを作成し、マルチモーダル、アンサンブルを行ってみようかなと思っています。
また、損失関数を自作(RMSE)に変えたところ、学習時間が同一モデルで1epochあたり2時間から1時間半に減りました。
GoogleColabの同時実行可能なノートブックが最高2つ(GPU, TPU ひとつずつ)だったため、複数モデルの学習が同時並行できそうです。
Xceptionモデルでの学習を引き続き行っていました。
トレーニングデータのLossが1.0程度まで下がり、MAEが1.0を切ったため、学習を止めました。
分類の学習の時にはテストデータの精度(Accuracy)も1epochごとにトレーニングデータのロスなどと同時に表示されていたのですが、MAEにしたところ表示されなくなったため、確認ができませんでした。
現在、画像の水増し(水平反転、ノイズ、ぼかし)を行い、6倍(約11000枚)に増やし、Xceptionモデルでの学習を行っています。
画像が圧倒的に増えたため、1epochが2時間かかっており、数日間放置するしかないかと見ています。
Google Colabのノートブックを1つ増やし、別のモデルでの学習や画像数を絞った学習を並行して行おうかなと考えてます。
中間発表前から学習を行っていたResNetモデルですが、200epochほど学習を行っても、100epoch後からLossやMAEがあまり変わらないため、中断しました。
今は植物図鑑でも使用したXceptionなどの他のモデルを試しています。
Xceptionでの学習ですが、クラッシュを避けるためbatchSizeを16に変更し
5epochの段階でval_loss, val_maeがResNetの学習よりも早く下がっているのでこのまま学習を行う予定です。
前回の進捗報告の際に教えていただいたGCPでの実行ですが、調査したところ64GBのGPUを1ヶ月借りると712ドル超はかかるそうです。
以下がComputeEngineのGPU価格です。
https://cloud.google.com/compute/gpus-pricing?hl=ja
今後精度が出ない場合には検討したいと思います。
引き続き学習を行っています。
以前は画像を一気に読み込んだ後に学習を行っていましたが、
バッチサイズごとに画像を読み込む方法に切り替えたことでクラッシュやエラーが起きなくなりましたが、GPUメモリ25GBのうちの90%ほどを使い切ってしまうため、他の方法も検討中です。
上の方法で学習を行うと以前見つけたData Augmentationライブラリ( Albumentations )をうまく使えないため、とりあえずはKerasに組み込まれているImageDataGeneratorを用いて水増しし、学習をしていく予定です。
糖度のデータに不備があったため、改めて学習をしています。
画像をGoogle Driveから読み出すのではなく、Google Colabのインスタンス上に画像をコピーしてから読み出すことでクラッシュの頻度が減りました。
中間発表までに学習をある程度終え、精度検証を行いたいと思います。
学習を続けています。
lossが3~4程度だと推定値が小数点第3位ぐらいしか差がない状態です
画像の量やサイズが大きいとGoogleColab上のGPU最上位モデルでもクラッシュしてしまうことがあるため、画像のサイズと量の調整などをしていきたいと思います。
また、画像の読み込み時間が長かったり、1epochあたり15分以上かかるので相当時間がかかりそうです。
https://qiita.com/hirune924/items/bfb099a704537b4e22ca
画像読み込みとData Augmentationに関しては上記の記事を参考にして高速化を図ってもいいのかなと思っています。
推定値が大きな値になってしまう原因はテストデータ(画像)の値を0から1に正規化せずに推定を行っていたという単純な理由でした。
原因を知らず新たにVgg19を再学習させていました。
その後、正規化をし上記のモデルで推定をすると9.75…という小数点3位以下の値が変わる程度の推定値になりました。
学習データの量が足りないのでデータを増やし、学習を行っています。