年末年始はVGG16とXceptionをFineTuningし、精度比較などを行っていました。
十分に画像があった既存の8クラスで学習を行いました。
サイズ (width, height, channel) = (192, 192, 3)
training_data 約2700枚
validation_data 約800枚
test_data 約320枚
epoch 約120
VGG16は下位2層 Xceptionは下位88層を学習
という環境で行いました。
validation_dataでの精度はVGG16で83% Xceptionで89.5%ほどでした。
このサイトを参考にし、混同行列を作成しました。
https://blog.aidemy.net/entry/2018/12/23/022554
丸々コピーしたところ、実行できず、自作モデル以外では
model.predict_classes()が使用できず、ここを1枚ずつmodel.predict()で結果をlistに追加することで動きました。
また、画像読み込みの際にImage.ImageDataGenerator.flow_from_directory()を用いるとフォルダ名をラベルにしてくれるのですが、以前やったラベルの順番と変わってしまい、このことに気づくのに時間がかかってしまいました。
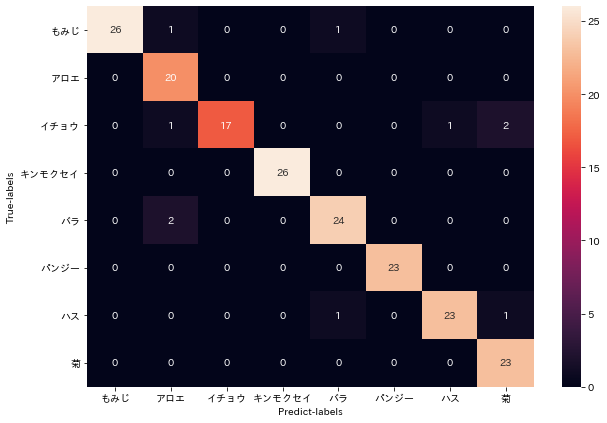
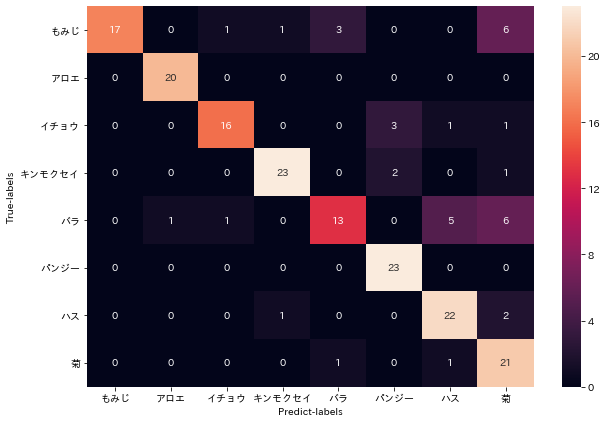
この時点でXceptionの方が精度が良いと判断し、これ以降はXceptionモデルで精度検証を行いました。
次にXceptionモデルの適合率、再現率、F値を出しました。以下が結果です。

イチョウのF値が一番低いため、どこの特徴を捉えているのかを知るために、
以下のサイトを参考にヒートマップを出しました。
https://qiita.com/T_Tao/items/0e869e440067518b6b58
まず、1枚目はイチョウと判別されたが、確率が低かった画像のヒートマップです。

次に、ハスと誤判別された画像のヒートマップです。

test_dataも悪い気もするのですが、他の誤判別された画像でヒートマップを表示したところ、関係ない背景の部分などの特徴を捉えてました。
現在、メンバーの二人が画像整形してくれたのと、加藤くんが追加で画像収集をしてくれているので、今後は種類を増やし、Xceptionで学習、精度検証をしたいと思っています。
また、training_dataの背景を単一色にし、学習させたら精度向上するのかなと思ったので、時間があれば、画像処理をかけて学習をさせようかと思っています